DMP Resources
Last updated on 2024-08-06 | Edit this page
Overview
Questions
- Where can one find Funder requirements?
- Example DMPs?
- Appropriate data repositories and data standards?
Objectives
- Find funder requirements for a DMP
- Successfully search for example DMPs
- Find FAIR data repositories appropriate for a patron’s research project
- Match a data type with appropriate data standards
Introduction
As librarians, we use a variety of resources to answer researchers’ questions, such as library databases like ERIC or PsycInfo, or reference sources like Credo. When answering data management plan questions, you will use a new set of resources. In this lesson, we will introduce you to places to find data management planning information to answer common researcher questions.
Funder Requirements
Funders are increasingly including DMPs in their requirements for grant applications. Due to the 2022 Ensuring Free, Immediate, and Equitable Access to Federally Funded Research memo, colloquially known as the “Nelson Memo”, all federal granting agencies in the US are required to establish data sharing policies. When assisting a researcher writing a DMP for a grant application, the first step is to get a handle on the funder’s requirements for the plan.
Here are some places to check for funder requirements:
The funding announcement. Most grant programs create an announcement, which may be called by any of a number of acronyms such as a “CFP” (call for proposals) or “NOFO” (Notice of funding opportunity) to publicize their funding opportunity. After navigating to the funding announcement, you can scan through the associated links to look for information on their data management plan requirements. Below, you can see the information provided in a National Institutes of Health Notice of Funding Opportunity:

In case the funding announcement does not have the information you need, proceed to the other items on this list.Funder application instructions or website. Large funders will have a website set up to help researchers through the application process. Looking through the documentation can help you understand their requirements for data management plans. This example from the NIH application instructions redirects you to sharing.nih.gov, their website specifically for data sharing:

The SPARC directory of data sharing requirements of federal agencies. SPARC stands for the Scholarly Publishing and Academic Resources Coalition, and is a non-profit that supports open research and education systems. Through this website, you can view and compare data sharing policies from top funding organizations.
Google search. Often googling “[funder name]” “data sharing requirements” OR “data management plan” OR “dmp” will direct you to the appropriate documentation.
Contact the funder. If you are still not sure about what guidance to follow, consider reaching out to the research office contact in the funding announcement.
Example DMPs
After locating the funder requirements, researchers may find it useful to see an example DMP written by others as part of their application to the same program or funding agency.
Here are some places to check when looking for example DMPs:
University libguides. Many research university libraries have created libguides that provide researchers with guidance on writing DMPs. Some library resources include boilerplate templates for specific funding agencies, or successfully funded researcher DMPs. To find university libguides, you can either search through the LibGuides Community or search google for DMP AND [funding agency] AND libguide.
DMPTool. The DMPTool is a free online application that helps guide researchers through writing plans, and even allows librarians to provide feedback along the way. The website maintains templates based on funder and program requirements, in addition to hosting public DMPs created by researchers using the DMPTool. In the public DMPs list, you can narrow your search by funding agency to find relevant examples. We will explore the DMPTool more in Episode 4.
Funder example DMPs. Some funding agencies, like the NIH, have created example DMPs to provide researchers an idea of what they would like to see as part of their grant applications. In addition, some granting agencies share data management plans submitted as part of grant applications through a public repository. An example of this is the Department of Transportation’s (DOT) repository & open science access portal (rosap).
Example DMS plans website. The Working Group on NIH DMSP Guidance created the Example DMS Plans website, which aggregated stable versions of publicly available DMPs. It was compiled ahead of the rollout of the NIH DMS Policy.
FAIR Data Repositories
In data management, we often speak of making data “FAIR.” FAIR is an acronym for Findable, Accessible, Interoperable and Reusable. Using these principles, we can evaluate the “openness” of a data set. Repositories should promote these characteristics in order to make data housed there user-friendly.
According to the NNLM’s data glossary, “a repository is a tool to share, preserve, and discover research outputs, including but not limited to data or datasets.” Generally, a data repository is a website that houses a collection of datasets, making them available to a broad(er) audience. Repositories manage data sharing infrastructure and provide a stable location for researchers to share their work.
Why choose a data repository? For most researchers, a data repository is the best practice for data sharing. Using a personal or lab website or even uploading the dataset in journal article supplementary files is not advisable because the long term sustainability of the website is unknown: it can be updated or taken down without warning. In addition, simply adding “available upon request” to the data availability statement in a publication is not sufficient. Studies have demonstrated a lack of author compliance when data is actually requested.
Callout
In addition to lack of sustainability, personal websites, article supplementary files and availability upon request are typically difficult to find. Data repositories mints DOIs, digital object identifiers, providing persistent access to data even if it is updated or moved, and will provide reasoning for removal if the dataset needs to be taken down. Data repositories also provide structures that link README files or other metadata schemas to the dataset, allowing for greater reusability in the future.
Through repositories, several options are available to researchers for data sharing:
- Public access. Public datasets are available to all without restriction. This is commonly used for animal studies or data without privacy concerns.
- Controlled access. In a controlled access repository, researchers must verify their identity before they are allowed to download and analyze data. This can take the form of verifying a university-associated email address, signing a data use agreement, or sending in an application before access is granted. Some repositories, such as Vivli, which specializes in clinical trial data, require that sensitive data be analyzed in a controlled cloud computing environment. Others, like ICPSR, may require that their restricted datasets be accessed on-site, using a computer not connected to the internet.
- Embargoes. Most repositories allow for datasets to be embargoed. Data sets may be embargoed for a number of reasons. For example, the researchers may not wish to publish their data until the accompanying article is available, or they may be pursuing a patent based on their discoveries.
Here are the types of data repositories that researchers can use for sharing data:
- Specialist data repository. Specialist data repositories accept scholarships from certain disciplines or on a specific topic. These include ICPSR, the inter-university consortium for political and social research.
- Generalist data repository. Generalist data repositories accept any scholarship from any discipline. These include Figshare, Zenodo, Mendeley, Harvard Dataverse, and OSF. Other generalist repositories include Vivli, which only accepts clinical data, and Dryad, which primarily accepts data from the sciences.
- Institutional data repository. Some institutions host their own data repository to encourage their researchers to deposit data. These are typically limited to affiliates of the host institution, though you should check if your researcher’s collaborators are affiliated with an institution hosting a data repository. Other institutional repositories, like the Harvard Dataverse, allow any researcher to deposit their datasets regardless of affiliation.
Callout
Institutional repositories vary in their ability to accept and maintain data. Before commiting to using an institutional repository, check that they routinely accept data.
Recommending a data repository for inclusion in a DMP can be challenging. Generally, it is best to recommend a specialist repository, followed by an institutional or generalist repository. Here are some tools to help you find the right data repository for your researcher:
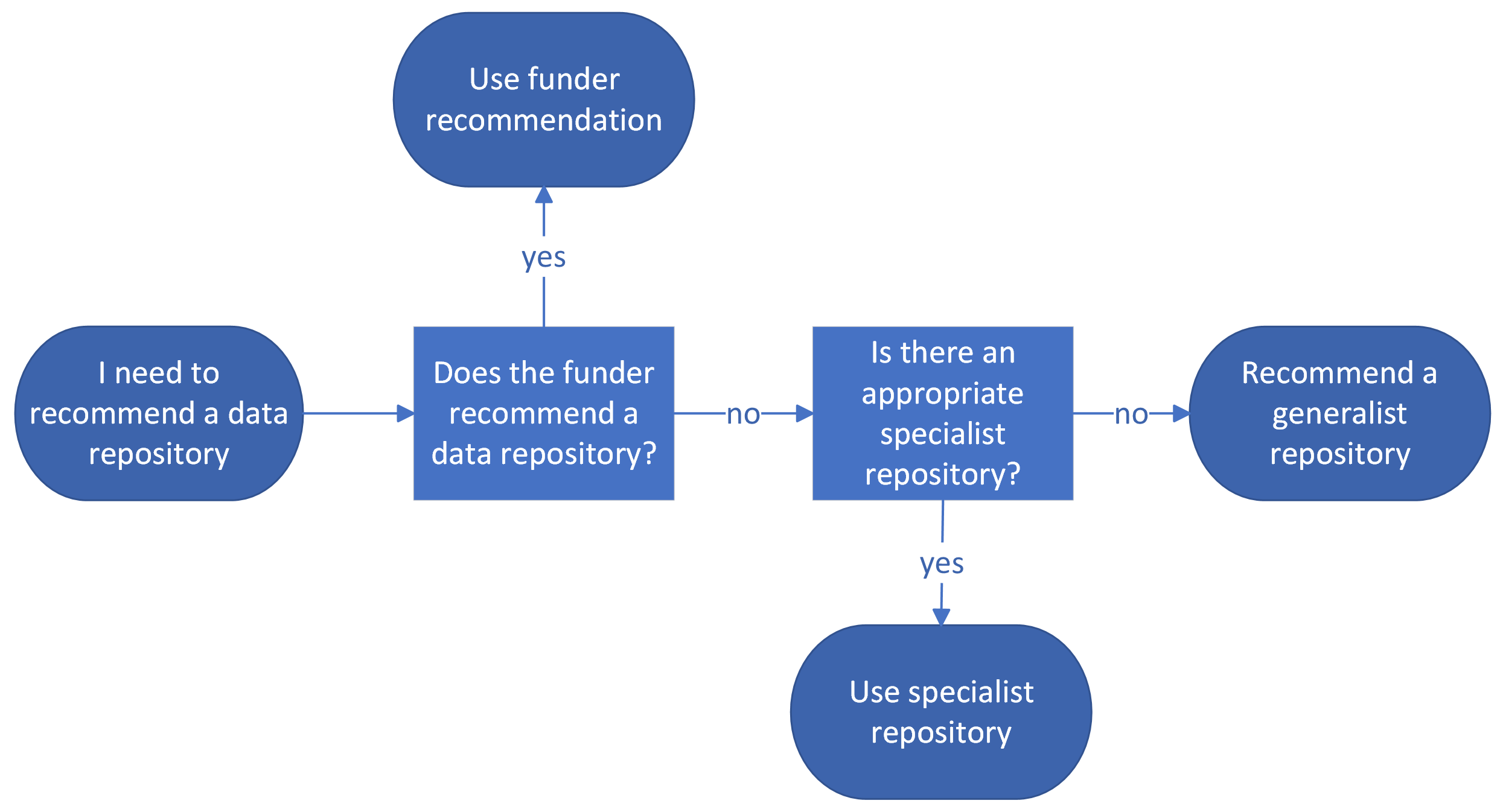
- Repository indices. Locating the right data repository for your researcher among the thousands in existence may be challenging, especially if you are not familiar with where others in the discipline are depositing their datasets. Luckily, there are a number of repository indices that aggregate data repositories and provide filters to facilitate pinpointing the one that works best for your researcher. FAIRsharing and re3data are good starting points when you are not aware if a specialist repository exists for a given discipline.
- Funder recommendations. Some funders like the AHA or the NIH provide recommendations for where their funded projects should share their data after the active research phase has concluded– the NNLM Data Repository Finder provides more guidance for finding an NIH-supported repository.
- Publisher recommendations. For researchers without funding or whose funders provided no guidance on which data repositories to use, some publishers like Nature have requirements where researchers should deposit their data before their articles are published.
Callout
Publishers requiring data deposit before article publication will also require a data availability statement, a description of where the dataset is publicly available, located at the bottom of the article.
Metadata and data standards
According to the NNLM data glossary, a data standard is “a type of standard, which is an agreed upon approach to allow for consistent measurement, qualification or exchange of an object, process, or unit of information. […] Data standards refer to methods of organizing, documenting, and formatting data in order to aid in data aggregation, sharing and reuse.”
Data standards help to promote the FAIR principles. By using a data standard when creating and describing their data, researchers make their data easier to discover and reuse. For instance, if you use a standardized survey instrument when collecting data, your data can be easily compared and combined with the results of other researchers using the same instrument.
Some of the most common data management questions data librarians receive revolve around standards. Many researchers, even if they support the principles of open science, are not trained to find and utilize data standards. Often, they are not thinking about their process from the point of view of data reuse. For librarians, data standards present an opportunity for us to educate researchers.
There are many types of data standards, including:
- File type. When curating a dataset to share, researchers should convert their data to an open file format. For instance, spreadsheets should be made available as a CSV rather than an excel document (XLSX). Using standardized open file types is a data standard.
- Controlled vocabularies/ontologies. A controlled vocabulary ensures data standardization by limiting the number of terms that can be used in a given field. Librarians often use controlled vocabularies when cataloging, for example MESH for medical subject terms, or the Getty AAT for art terms. Researchers can also use controlled vocabularies in their work to ensure interoperability across studies.
- Minimum information. Minimum information standards, such as the MINSEQE, specify the minimum amount of metadata and data required for different data types. This helps to facilitate reuse and prevent mystery datasets without documentation from coming into a repository.
- Metadata schema. A metadata schema defines the elements of metadata for an object and how those elements can be used to describe a specific resource. Many librarians are familiar with metadata schemas such as MARC or Dublin Core, but there are also specialized metadata schemas for particular research fields.
Finding appropriate data standards can be tricky for both librarians and researchers. The data standard landscape is still evolving, and the availability of data standards varies widely by field. There may be no widely accepted standard for a researcher’s project. If there is a lack of appropriate data standards, this information should be included in the DMP.
One strategy when answering reference questions about data standards is to work backwards. If you or the researcher have already picked out a data repository, look in the documentation of that repository to find what data standards they are using. For example, the NIMH National Data Archive has a page describing their data standards.
If working backwards isn’t possible, here are some resources to find data standards:
- Research data alliance metadata standards catalog
- Fairsharing has a registry of standards
- Bioportal Ontologies catalogs ontologies, with a biomedical focus
- DCC guide to disciplinary metadata standards catalogs standards, tools, and use cases by subject area
Quiz
As part of an intervention study, a researcher will be conducting surveys of adolescents in the juvenile justice system who have exhibited suicidal behavior. In addition to surveys, there will be in-depth interviews with some of the research subjects. The results will eventually be published in a peer-reviewed journal. Accordingly, the datasets will be shared and preserved. The researcher has learned that their University has an institutional repository that has not typically collected scientific data.
Which of the data types mentioned would be applicable to the data management plan?
- The interviews (qualitative)
- The survey data (quantitative)
- Both
- Both
What aspects of managing and sharing this data should this researcher consider as they prepare their data management plan?
- The choice of repository.
- Usage of standard questionnaires for the survey.
- Facilitating the potential reuse of the data.
- All of the above
- All of the above
ICPSR
The example study contains sensitive data because it deals with a non-adult incarcerated sample exhibiting suicidal behavior. In order to be shared, it requires additional safeguards. Dryad does not have a controlled access feature and therefore is not an appropriate choice in this case. ICPSR aligns more with the discipline of this study, and requires researcher screening and secure access before data can be viewed.
- Answers will vary, but one acceptable response is Vivli. To find which data repositories accept clinical trial data, use the NNLM data repository finder and check off “Clinical Trials” under question 4.
- Answers will vary. We can see Vivli’s guidance on data standards%20used%20for%20analysis.), where they recommend following CDISC standards.
Key Points
- Librarians need to be able to find funder requirements, example DMPs, data repositories and data standards to answer researcher questions.